Minimalist flashcards with Anki and Obsidian
Over the last 3 months, I've spent 2h/day playing with Anki and Flashcards.
I'm used to store my notes in Obsidian. With the plugin Obsidian_to_anki, you can write flashcards directly in Obsidian by using some delimiters. The plugin is then able to parse your notes and synchronize the flashcard with Anki. so you can study them anywhere (in the bus, waiting at the train station, ...).
I've ended up with a smooth workflow. But I couldn't get used to the noise that the delimiters create around the cards.
I didn't find how to customize obsidian2anki the way I wanted.
So I've coded my solution 👇.
Before / after
Here is a before/after of the note Booléens (bool).md.
The note contains metadata (MOC, source, date ...) and four flashcards.
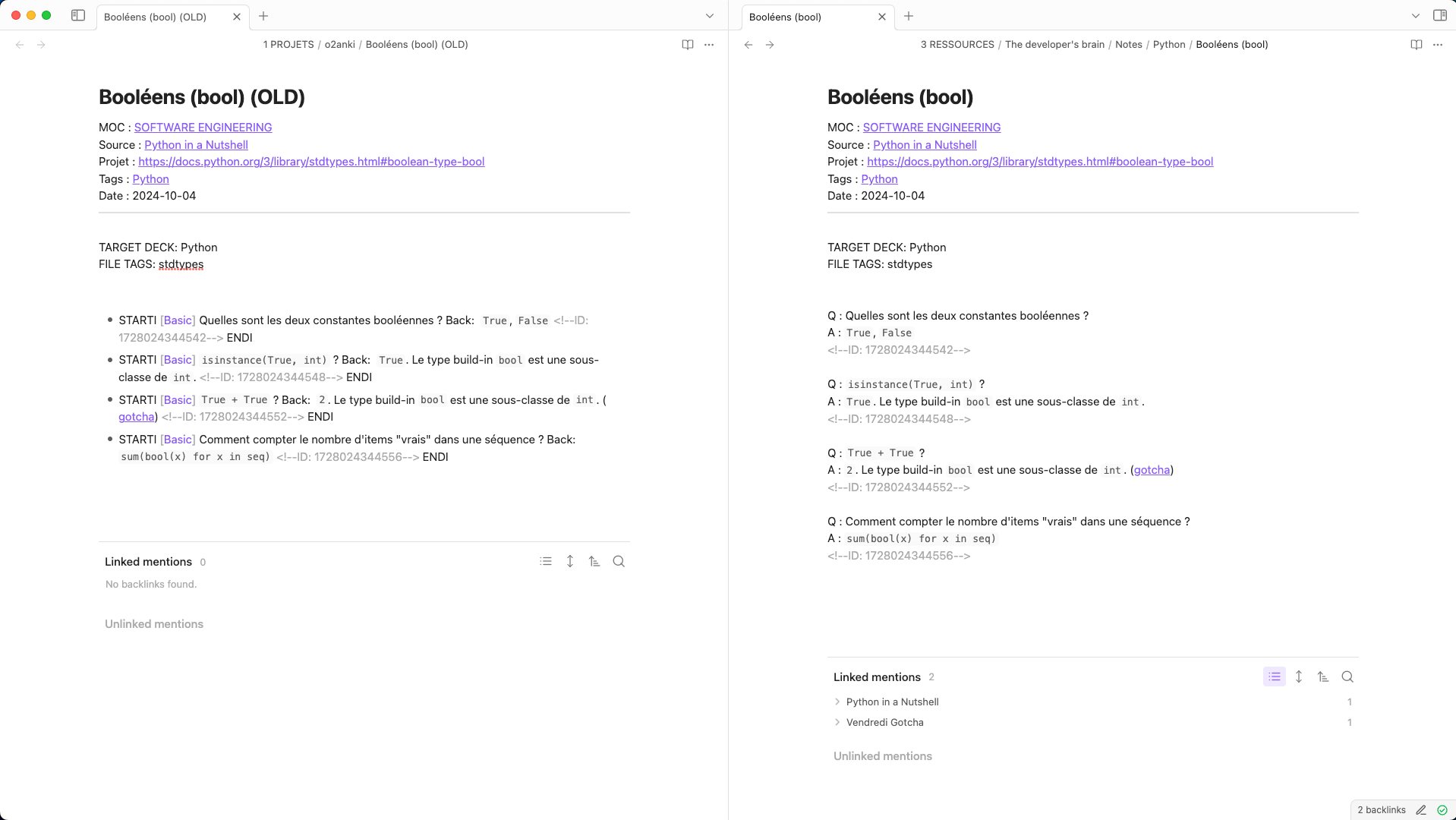
On the left is before. Delimiters STARTI [Basic], Back: and ENDI create noise and makes the reading experience painful.
On the right is after :
- we get a lightweight formatting, with juste
Q :andA :delimiters - question an answer get one line each. The goal is to keep them short
- I've added empty lines between questions
I didn't get rid of the <!--ID: XXXX--> tag. It tells if the note exist in Anki. When I update the deck, if the note exist, I update it rather than creating a new one.
There is a way to get rid of this tag : you recreate the deck from scratch each time you synchronize it. It's radical because this way you lose information about your progress. But I can do the job.
Speaking about the logic, here is how it works.
Architecture of the program
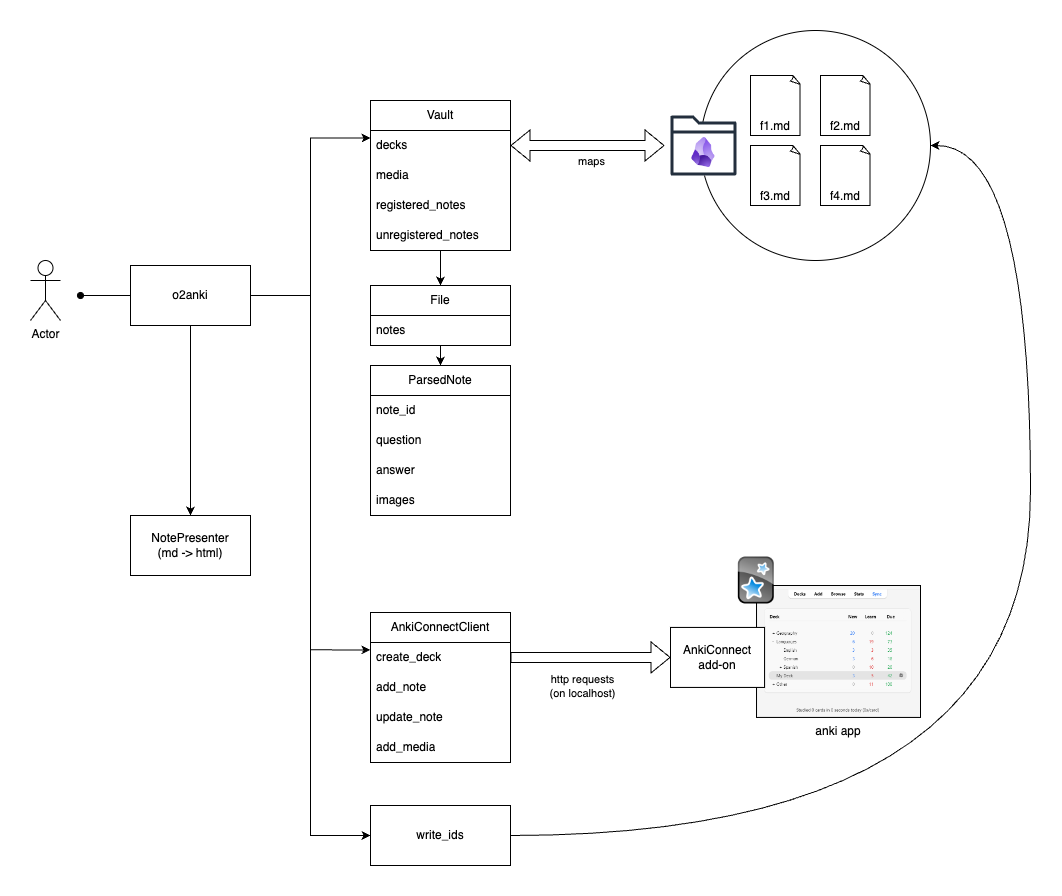
Roughly :
o2ankiis the orchestrator / the main programo2ankitakes in a path to a folder and analyse the*.mdfiles it containso2ankimaps the files into structured objects (Vault,File, andParsedNote)o2ankiupdates and creates the notes in Anki throughAnkiConnectClient- the
AnkiConnectadd-on receive the http requests and deals with Anki - the
NotePresenterclass transform the markdown-formatted text into html write_idsfunction writes the<!--ID: XXXX-->tags in the*.mdfiles
So far, I've favored design clarity over efficiency. I consider I lose my time if I try to optimize before I have a perfectly clear understanding of the problem and it's edge-cases. Also, runs I've made until now have been really fast.
Performance is not a bottleneck at this stage. But understanding the problem and choosing where to start has been.
Some tips if you want to run into similar problems
If I had to do it again, here are the steps I would follow :
- Take a few minutes to identify the usecases :
- creating a new basic note
- updating an existing note
- deleting a note
- creating a note that contains an image
- creating a note that contains code
- ignoring files in a given folder
- parsing note with question on several lines
- parsing note with answer on several lines
- parsing note followed by some unrelated text
- Consider the anki module. AnkiConnect looks like an unnecessary level of abstraction for this use-case. Using it reminds me a bit of the over-engineering story behind psycopg.
- If AnkiConnect is the solution, then start by playing with the api manually (see some example of exploratory commands with raw json body)
- Export some notes created with Obsidian_to_Anki in order to grasp their formatting :
Anki > Browse > Select a card > Right Click > Notes > Export notes ... > Notes in plain text > Export ...(see : export a card with code, export of a card with an image) - Implement the parsing in TDD using tailor-made files (see : testing the parsing of a single file)
- Code the orchestration (o2anki)
- Manage a deck with this solution for a few days to test it!
Conclusion
I've implemented a limited set of features. Just what I need. And I like the simplicity it makes.
I've planned to add some features, like adding DELETE: ID tag handling, adding css and code_hilite in code blocs. But my intent is to keep it focus. Complexity bumps when you try to do everything and please everybody.
If you want to have a look at the code : https://github.com/petitapetitio/o2anki
Laisser une réponse